
. Unlock the full potential of Llama 2 with our developer documentation. . Cannot retrieve latest commit at this time 126 lines 102 loc 686 KB. Web Meta developed and publicly released the Llama 2 family of large language models LLMs a collection of pretrained and. Go to the Llama-2 download page and agree to the License. Web A notebook on how to fine-tune the Llama 2 model with QLoRa TRL and Korean text classification dataset. Web Llama 2 is an enhanced language model that boasts notable advancements compared to its predecessor launched..

Ars Technica
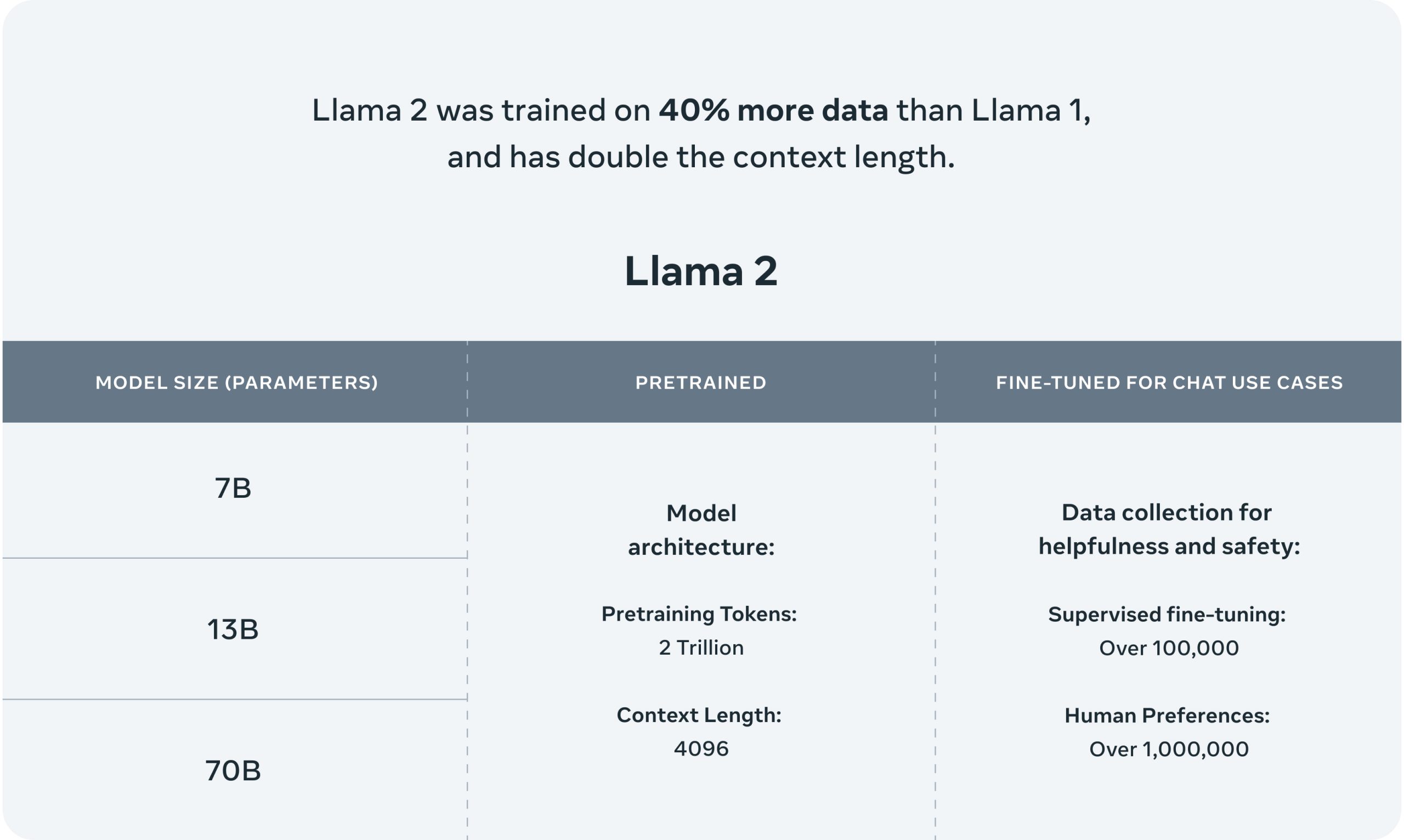
Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7 billion to 70 billion parameters Below you can find and download LLama 2 specialized. Our open source large language model is now free and available for research and commercial use. Web Our latest version of Llama Llama 2 is now accessible to individuals creators researchers and businesses so they can experiment innovate and scale their ideas responsibly. Web Llama 2 means the foundational large language models and software and algorithms including machine-learning model code trained model weights inference-enabling code training. Web Chat with Llama 2 70B Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles or even name your..
Web Whats the difference between Llama 2 7b 13b and 70b Posted August 4 2023 by zeke. Web Mistral 7B shines in its adaptability and performance on various benchmarks while Llama 2 13B excels. Web Llama 2 Instruct - 7B vs 13B How good are the Llama 2 Instruct models and how significant is the. Web All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have. Web First Llama 27Bs performance appears to be higher than Llama 213B in a zero-shot and few. Web It has been said that Mistral 7B models surpass LLama 2 13B models and while thats probably true for many cases. The Mistral AI team has unveiled the remarkable Mistral 7B an open. ..
Ars Technica
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. The LLaMA-2 paper describes the architecture in good detail to help data scientists recreate fine-tune the models Unlike OpenAI papers where you have to deduce it. We introduce LLaMA a collection of foundation language models ranging from 7B to 65B parameters We train our models on trillions of tokens and show that it is. The abstract from the paper is the following In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7. Open source free for research and commercial use Were unlocking the power of these large language models Our latest version of Llama Llama 2 is now accessible to individuals..




Comments